We chose source materials using our own judgement and local knowledge about which references seemed useful enough to inform this prototype.
Dataset browser
Tartu Safety dataset
Interactive table view sourced from tartu_risk_dataset_2.csv.
Rows
-
Districts
-
Dataset window
-
Source status
Loading
Critical methodology explanation
This dataset is not neutral
The dataset was created through many subjective human choices. Those choices directly shape what the model sees, what it ignores, and therefore what outcomes it can produce.
We defined the dataset features through subjective human decisions about which variables mattered and how they should be represented.
We used subjective local know-how to categorize each suburb for features such as
foot_traffic, area_type, socially_vulnerable_zone,
minorities_zone, student_zone, and nightlife_zone.
All of this human data work directly affects the outcomes. There is no neutrality here: small human interactions accumulated while this dataset was created.
Reference data provenance
This prototype dataset is synthetic, but it is partly informed by real public reference data from Tartu and police-related published materials.
Police callout reference
Incident pattern assumptions are partly grounded in published Väljakutsed material, where the stated public data source is the police tactical management database KILP.
Open official Väljakutsed sourceTartu open data reference
District-level context also draws on Tartu open data, including 2025 rahvastik linnaosa andmed published by Tartu Linnavalitsus.
Open Tartu avaandmed sourceVisual analysis
Dataset plots
The plots below are the same generated views used in the standalone dataset visual package.
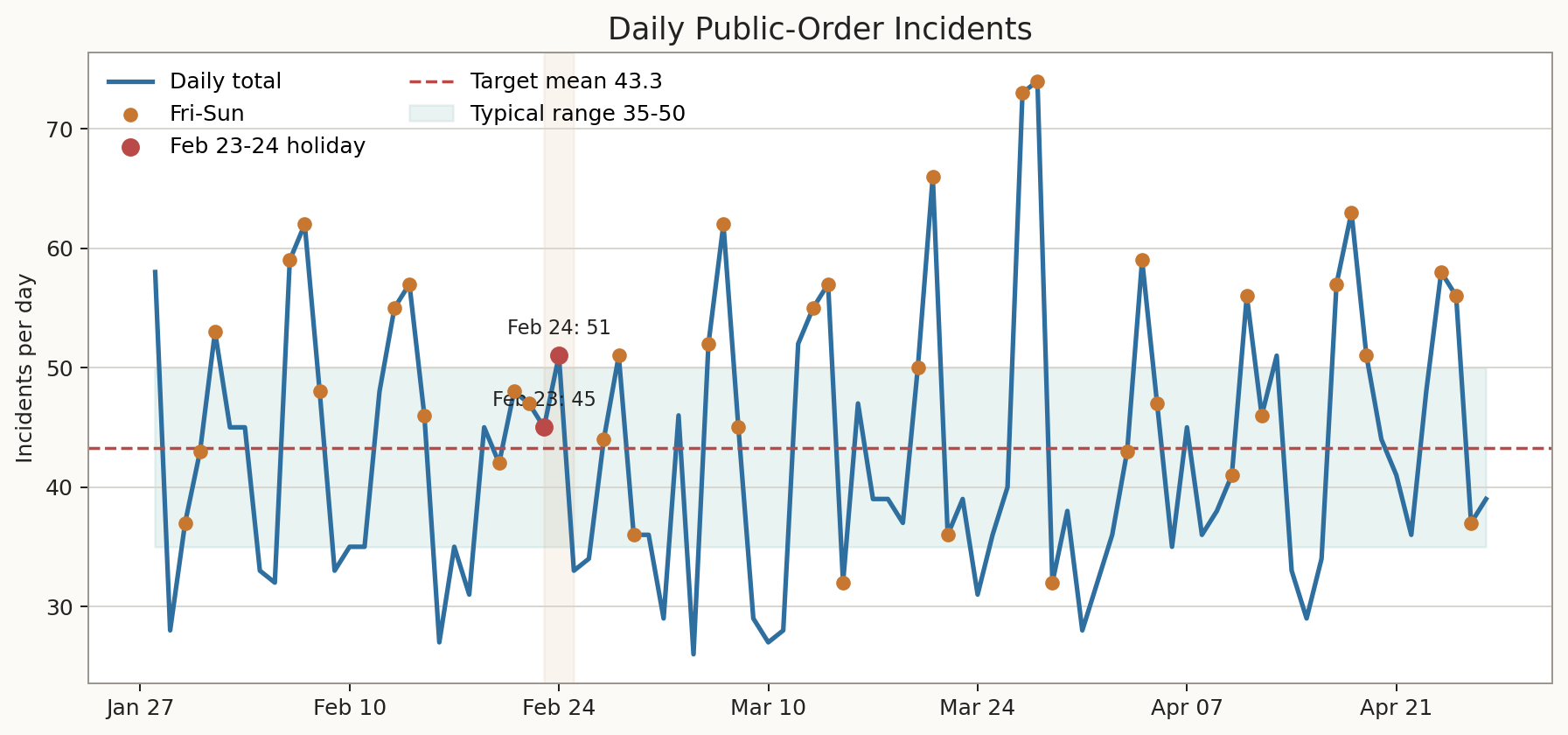
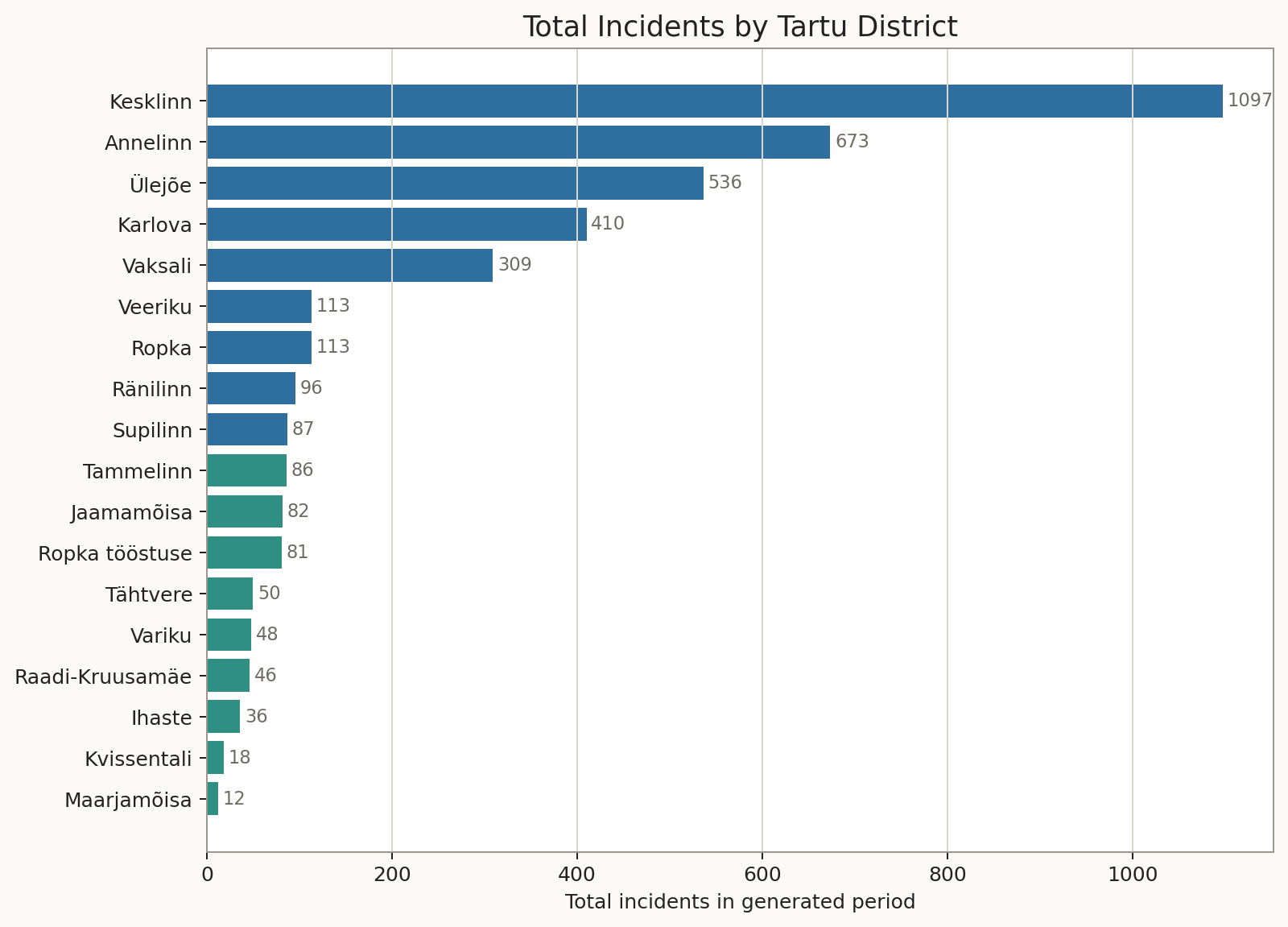
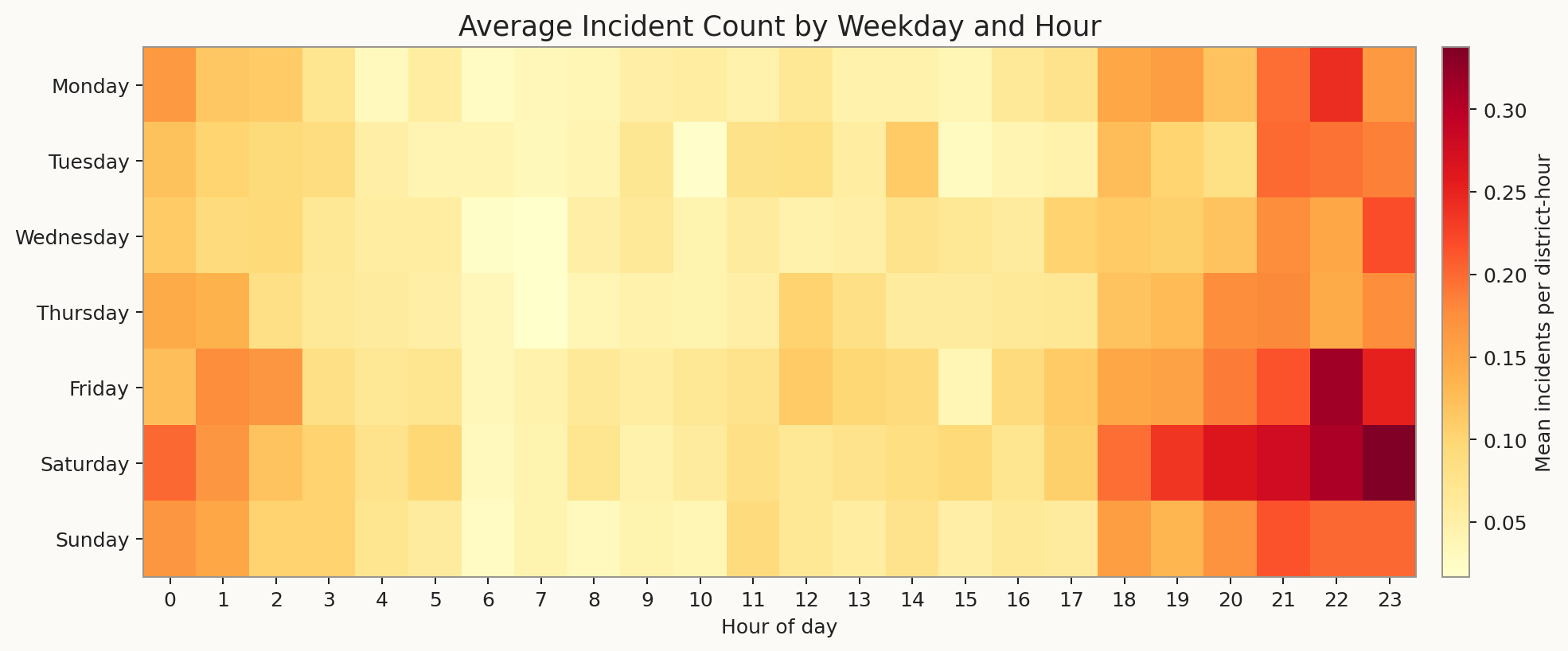
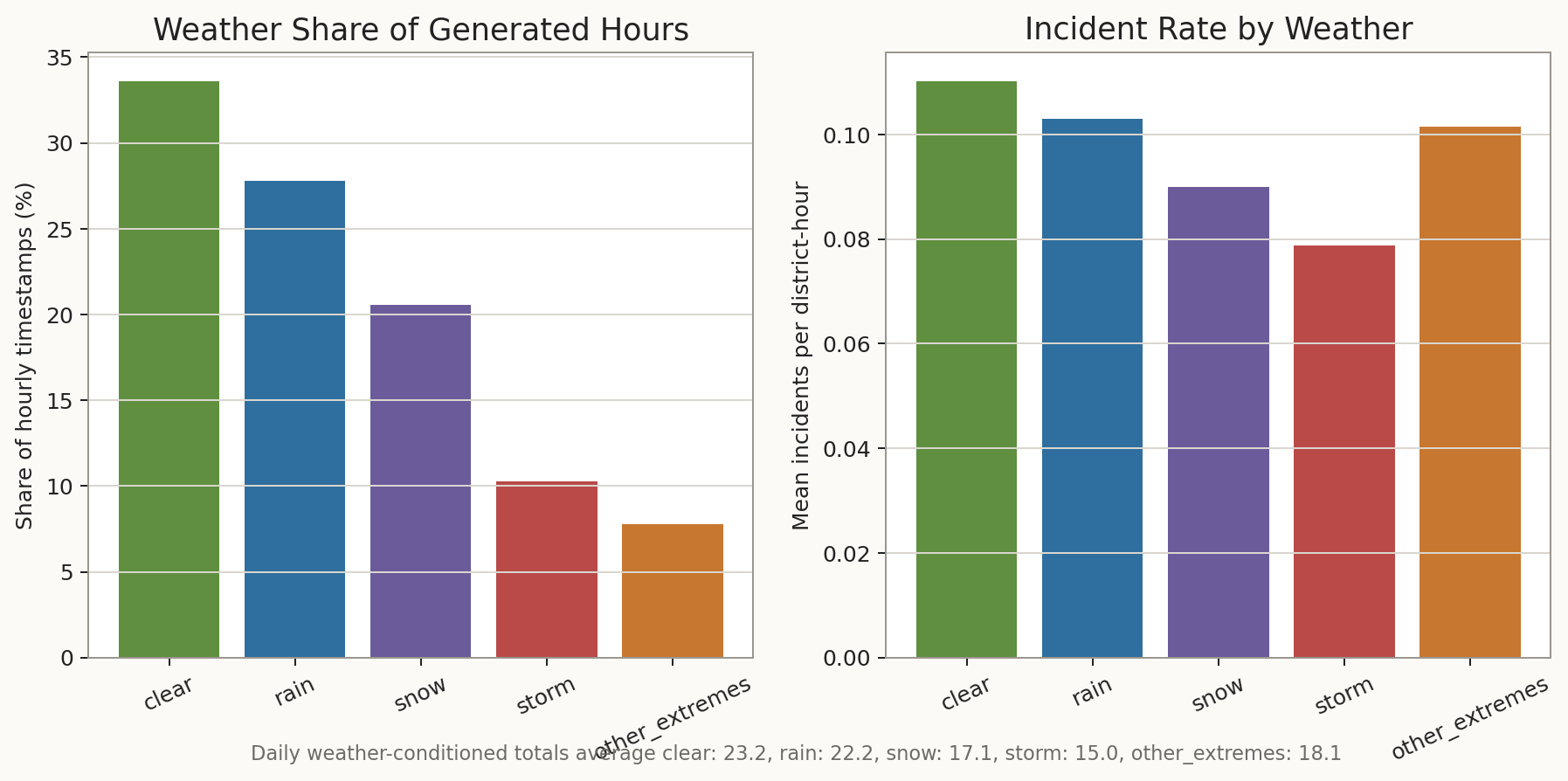
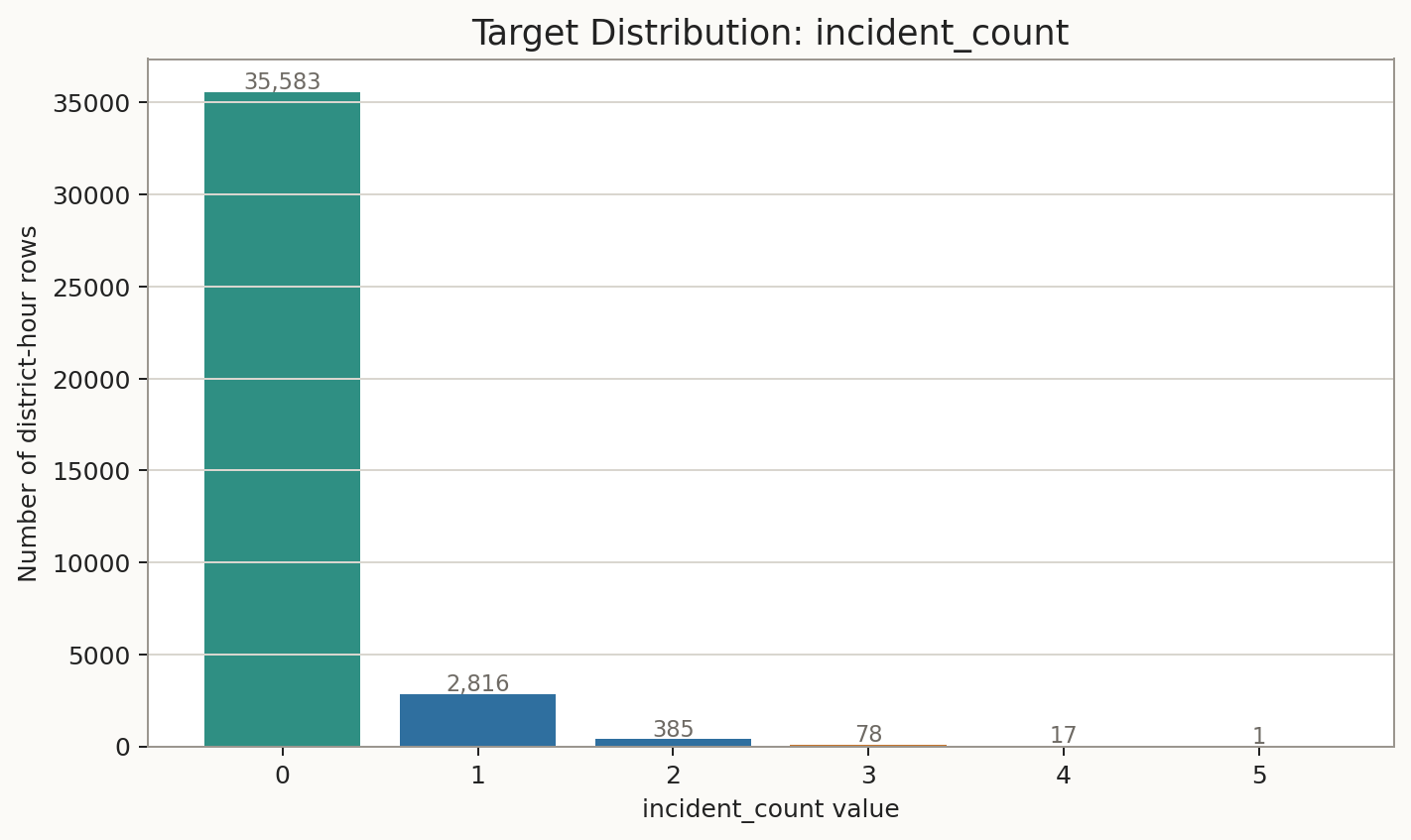
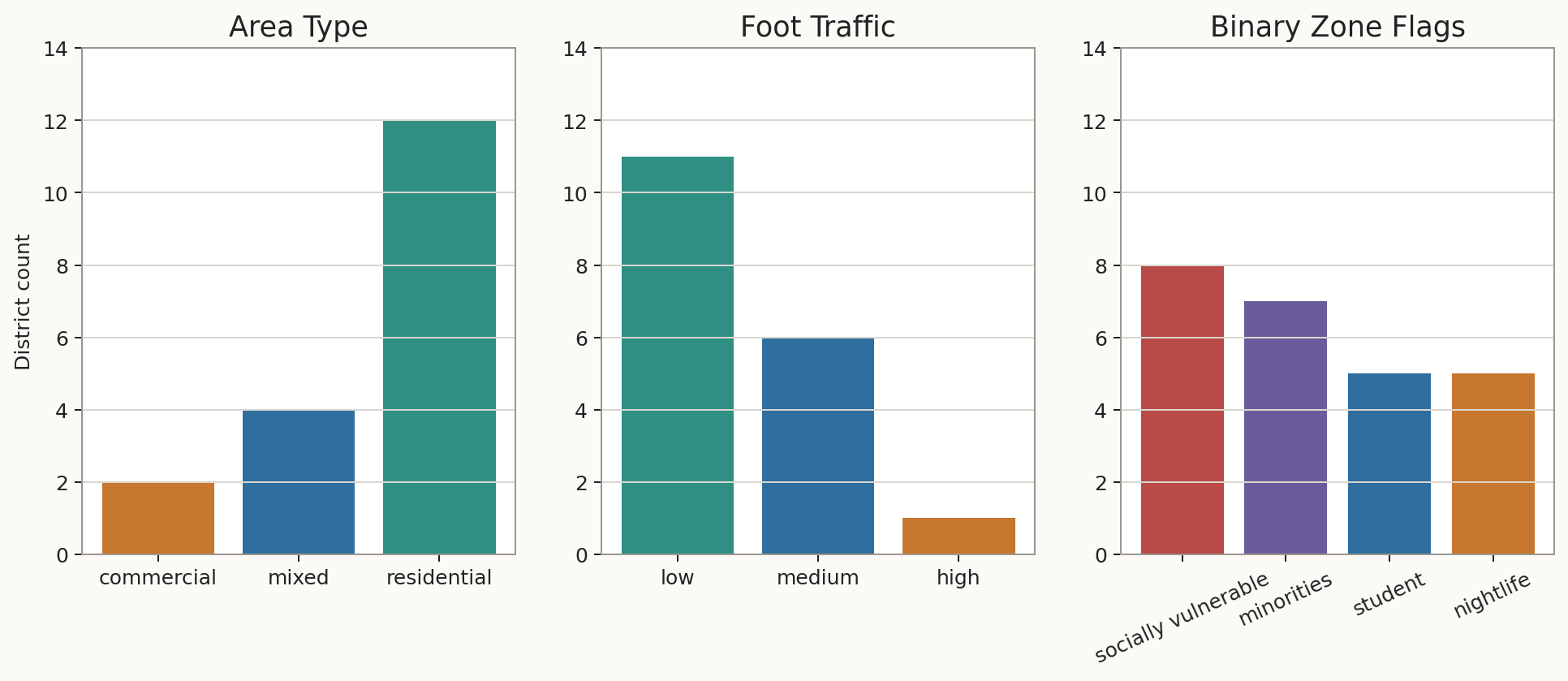
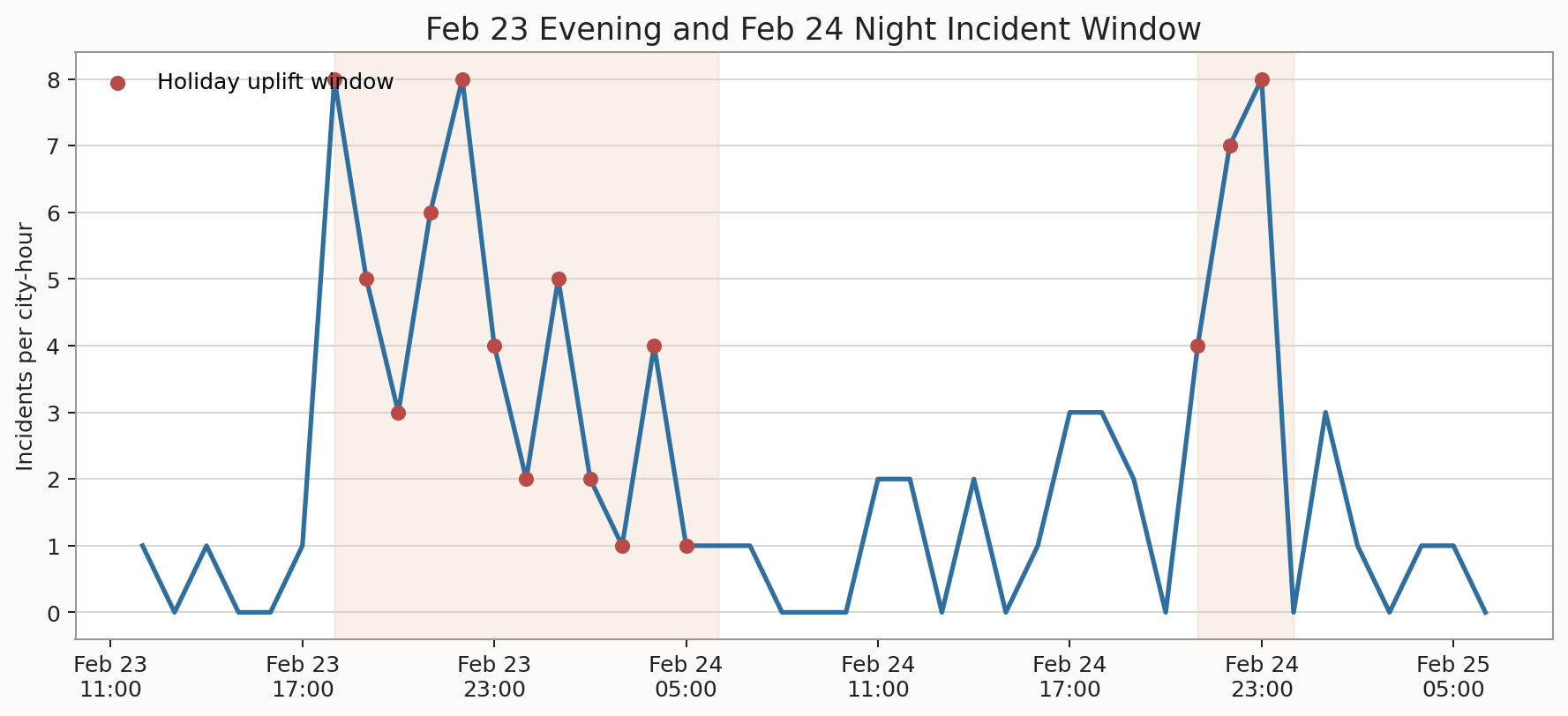
Full dataset
Download the full CSV from GitHub
Download the complete tartu_risk_dataset_2.csv file directly from GitHub raw content.